정의
Neural Machine Translation with attention 을 의역하면 다음과 같다.
Sequence(input)에서 어디에 집중하여 인공신경망을 이용한 번역을 할 것인지의 관점에서 구현된 구조
Seq2Seq Architecture
간단히 Seq2Seq 구조에 대해 정리하자.
기존에 정리해놓았던 글을 인용해왔다.
Seq2Seq은 시퀀스(sequence) 데이터를 다루는데 주로 사용된다.
가령, machine translation같은 작업에서 주로 사용되는데 영어를 불어로 바꾼다는 등의 task를 수행하기도 한다.
이를 위해 모델은 입력과 출력 간의 sequence mapping을 학습한다.
이 때 위에서 간단히 언급한 바와 같이 모델은 시간적인 의존성(Temporal dependency)을 학습해야 하기 때문에, decoder의 출력을 생성할 때 이전 생성된 출력 정보에 대한 고려가 필요한데 이를 위해 Attention이 등장한다.
즉, Context vector C가 fixed-length 였던 것을 감안하여 C(t)를 attention score를 계산함으로써 다르게 표현하여 시간적 의존성을 학습한다.

Reference: https://24bean.tistory.com/entry/Autoencoder-VS-Seq2Seq-차이-비교
Autoencoder VS Seq2Seq 차이 비교
개요 Autoencoder와 Seq2Seq 모두 encoder-decoder 구조로 되어있다는 점이 유사하지만 차이점이 명확한 서로 다른 두 구조이다. 가장 큰 차이점으로는 목적과 구조적인 차이가 있다. Autoencoder는 데이터를
24bean.tistory.com
Attention Mechanism
해당 포스트에서는 Transformer Architecture의 Attention보다는 Bahdanau의 개념적인 Attention을 적용하여 Attention을 이용한 NN Machine Tranlsation을 이해해보려한다.
이 또한 기존에 정리해놓았던 글에서 인용해왔다.
" decoder에서 단어를 예측하는 모든 step마다 encoder의 input sequence를 이용하는 것, 이 때 encoder에서 가장 관련이 높은 정보를(the most relevant information) 확인할 수 있도록 하자 "
Reference: https://24bean.tistory.com/entry/Attention-어텐션이란-무엇인가-분량-주의
Attention / 어텐션이란 무엇인가? (분량 주의)
선행 지식 (Pre-requirement) RNN https://wikidocs.net/22886 - (딥러닝을 이용한 자연어 처리 입문) https://arxiv.org/abs/1808.03314 - (RNN paper) LSTM https://wikidocs.net/22888 - (딥러닝을 이용한 자연어 처리 입문) http://www.b
24bean.tistory.com
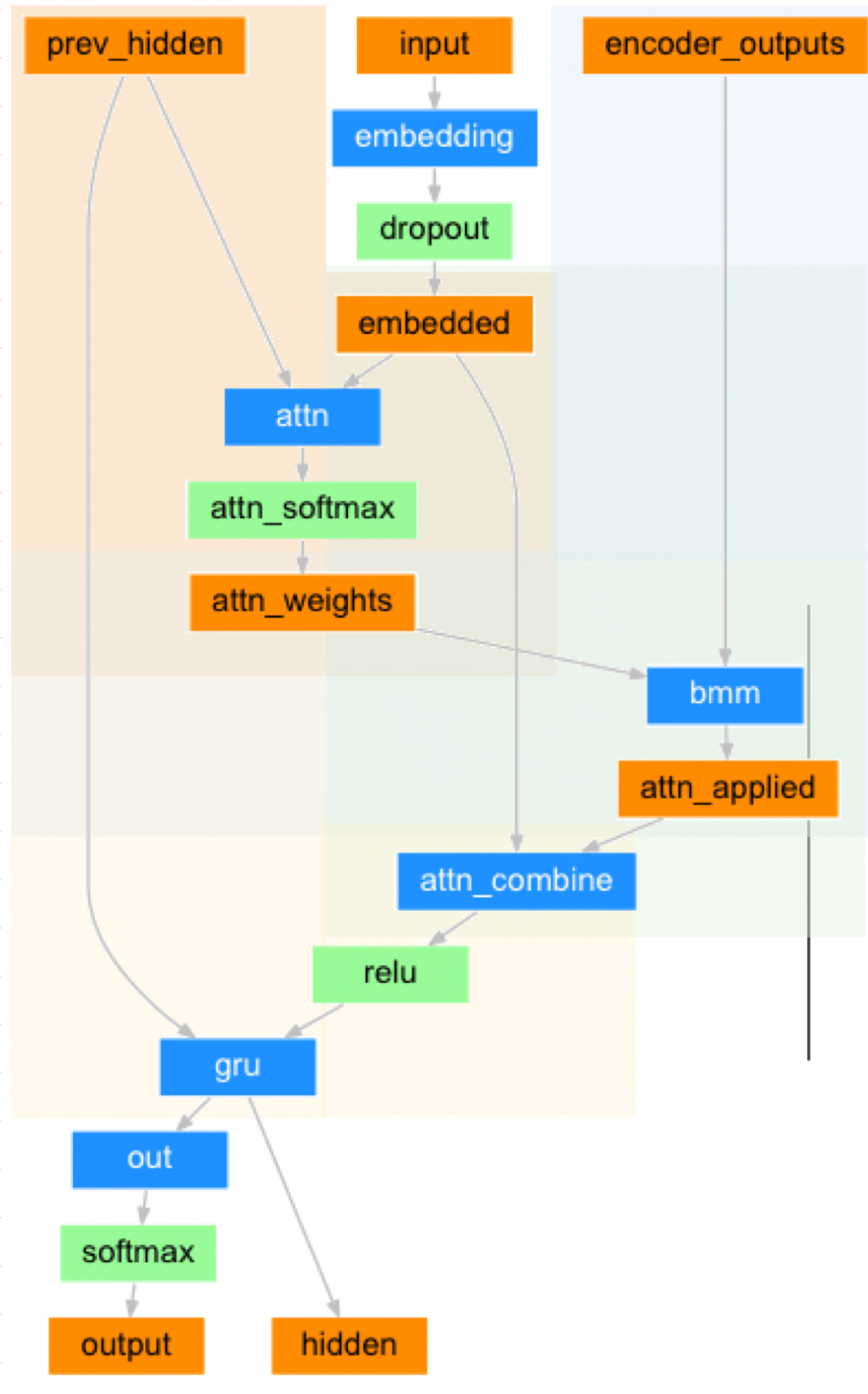
Training Process
1. Forward Pass (Encoding):
- 전처리된(preprocessed) 입력 문장을 encoder의 Input으로 사용
- encoder는 input sequence를 처리하고 context vector(encoded input sequence)를 생성한다.
2. Decoder Initialization:
- decoder의 첫 hidden state를 context vector를 사용하여 initialize
3. Decoder Step:
- 각 decoding step마다, Attention score를 계산한다. 이때 각 step마다의 decoder hidden state와 encoder hidden state를 비교하며 계산.
- Attention score는 input sequence와 현재 decoding step간의 관게를 나타낸다.
4. Context Vector Calcuation:
- weighted sum operation을 이용하여 attention score와 encoded input sequence를 합쳐준다 (combine / concatenate)
- 다시, 현재 decoding step과 encoded input 간의 관계를 나태는 context vector를 얻는다.
5. Attention Decoder Step:
- context vector, 이전 decoder의 hidden state, 직전에 생성된 단어(teacher-forcing의 경우 해당 안됨)를 decoder의 input으로 넣어준다.
- target vocabulary에 대한 predicted distribution 계산 및 다음 hidden state 생성
6. Loss Calculation:
- predicted target과 ground truth 비교 및 loss 계산
7. Backpropagation
- Decoder와 Attention mechanism을 지나게 loss backwoard propagation
- Gradient 계산
- Optimzation with SGD or Adam stuff
8. Repeat 3-7:
학습 프로세스 간, attention score는 decoding과 함께(simultaneously) 계산된다.
Attention score는 주어진 각 decoding step에 encoded input sequence 중 어느 단어에 "집중"할 것인지를 결정한다.
이를 통해 decoder는 target translation을 생성하는 과정에서 어떤 부분에 집중해야하는 지 알 수 있다.
Attention score를 계산하고 이를 통해 context vector를 계산함으로써, decoder는 input sequence에 dynamically Attention 할 수 있다.
즉, Attention을 통해 Input seqeunce의 length에 dynamic하게 대응할 수 있다.
이것이 Attention을 쓰고 안쓰고의 가장 큰 차이인데, 이를 통해 accuracy의 차이를 얻는다.
'MACHINE LEARNING > Artificial Neural Network' 카테고리의 다른 글
| Microsoft LIDA 사용법 (0) | 2023.09.03 |
|---|---|
| Time Series Transformer 의미 및 모델 (0) | 2023.05.09 |
| Neural Radiance Fields (NeRF) Tutorial in 100 lines of PyTorch code 주석 및 해석 (0) | 2023.04.30 |
| Autoencoder VS Seq2Seq 차이 비교 (0) | 2023.04.13 |
| TSC / Time series classification 시계열 분류 정리 (0) | 2023.03.10 |