딥러닝에 대한 전반적인 이해를 가지고 계신 분을 위한 포스트입니다.
흐름들을 복습하는 차원에서 읽는 것을 추천하며, 자세한 내용보단 간략한 정리에 초점을 맞추어 작성했음을 알려드립니다!😄
Large Scale Deep Learning
Deep Learning은 connectionism 철학에 기반한 학문입니다. 모든 뉴런들이 서로 연결되어있기 때문이다.
그래서 각각의 뉴런들의 상호작용으로 현명한 행동을 하는 네트워크를 구성하는 것을 목표로 한다.
neural network의 가장 중요한 요소는 결국 정확성과 복잡성을 해결하는 능력이다.
이를 위해 다음과 같은 노력들이 있었다.
- Fast CPU Implementations
- GPU Implementations
- Large Scale Distributed Implementations
- Model Compression
- Dynamic Structure
- Specialized Hardware Implementations of Deep Networks
특히 GPU의 발전이 매우 큰 영향을 미쳤는데 matrix multiplication과 division on many vertices in parallel to convert 3-D coordinates into 2-D on-screen coordinate 과 같은 특징들이 가장 주요했다.
독립적인 computation은 parallelization을 통해 학습 속도의 괄목할만한 성능 향상을 이끌었으며,
NVIDIA의 CUDA programming language 또한 간편한 프로그래밍 모델 생성, 거대한 parallelism, 그리고 high memory bandwidth를 가능케 했다.
Model Compression의 관점에서는 Pruning과 Distillation
Dynamic strcutured의 관점에서는 boosting, code branching 등을 통해 성능 향상을 이루었다.
* pruning과 distillation 참고
https://seongkyun.github.io/study/2019/04/16/model_comp_1/
Model compression(Pruning/Distillation) 정리 · Seongkyun Han's blog
seongkyun.github.io
Computer Vision
Computer vision은 이미지를 다루는 분야이다.
사용되는 분야에는 대표적으로
- object recognition
- detection of some form
- annotating an image with bouding boxes
- labeling each pixel with the identity of the object
- etc..
Preprocessing의 관점에서 computer vision은 이미지를 다루는 분야이므로 해당 이미지를 학습하기 위해 적절히 전처리할 필요가 있다.
이미지의 같은 스케일로의 formatting은 필수적이다.
data augmentation 또한 좋은 generalization 방법이 될 수 있다.
이때 contrast normalization도 적용해 볼 수 있는데 다음과 같은 식을 통해 표현되며 3은 RGB를 나타낸다.

위의 수식에 대한 다양한 variation 또한 존재하는데 global contrast normalization이나 local contrast normalization이 그 예시이다.
Speech Recognition
화자의 발화를 통한 acoustic signal을 sequence of words로 매핑하는 것을 의미한다.

Natural Language Processing
human languages를 컴퓨터에 의해 handling하는 것을 의미한다.
대부분의 NLP application은 확률분포에 의해 정의된다.
extremely high-dimensional and sparse discrete space 위에서 operate하기 때문에 Computational and statistical sense가 필요하다.
n-grams기반 모델은 conditional probability of the n-th token을 갖는다.
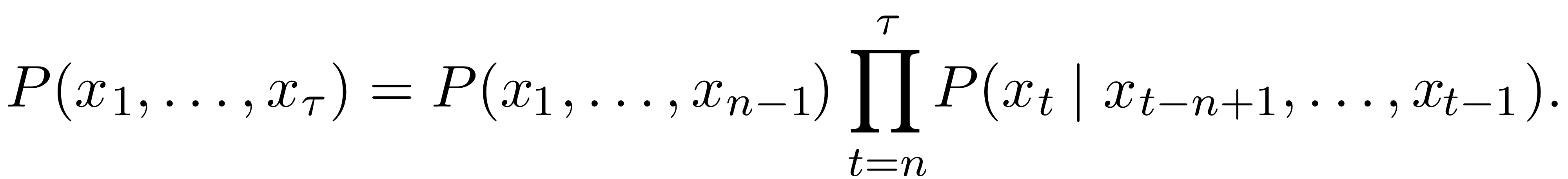
The decomposition is justified by the chain rule of probability.
n-gram학습은 단순한 카운팅을 통한 amximum likelihood estimate를 이용하기에 매우 단순하며 curse of dimensionality 문제가 있다.
따라서 neural language model이 필수적이다는 관점이 지배적이다.
이때 우리는 word embedding이라는 개념을 등장시킴으로써 해당 문제를 해결하고자 했다.

그 이후 encoder-decoder 구조의 등장으로 더욱 향상된 성능의 neural machine translation이 가능해졌으며
attention mechanism을 통해 sequnce간의 관계를 유추하는 능력이 더욱 좋아졌다.
'MACHINE LEARNING > Artificial Neural Network' 카테고리의 다른 글
| TSC / Time series classification 시계열 분류 정리 (0) | 2023.03.10 |
|---|---|
| Likelihood, posteriori, prior (+Bayesian Statistics) 연관성 정리 (0) | 2023.02.08 |
| Sequence Modeling : Recurrent & Recursive Nets as RNN (0) | 2023.01.16 |
| Sequence Modeling : Recurrent & Recursive Nets as introduction (0) | 2023.01.15 |
| Attention / 어텐션이란 무엇인가? (분량 주의) (0) | 2023.01.09 |