Metric 종류 및 특징
일반적으로 ML(Machine Learning)에서는 모델의 category에 따라 Metric을 각각 다르게 정의합니다.
말 그대로 하는 일들이 다르기 때문에 평가 기준의 역할을 하는 Metric이 달라집니다.
대표적으로 사용되는 Metric 몇가지를 각 cateogory별로 정리하겠습니다.
ML의 대표적인 task는 다음과 같이 정의됩니다.
- Classification
- Regression
- Ranking
- Statistical
- CV (Computer Vision)
- NLP (Natural Language Processing)
- Deep learning related
- etc...
해당 포스트에서 언급하지 않은 Metric도 다수 존재합니다. 모든 평가기준을 다룰 수는 없으니 대표적인 것들을 정리하고 추가적인 정보를 원하시면 다른 포스트를 참고해주시길 바랍니다.
Classification
Classification은 Binary하거나 혹은 multi-class에 적용하는 ML의 대표 Category입니다.
해당 task에 주로 사용되는 모델로는
- SVM (Support Vector Machine)
- Logistic regression - regression이지만 실질적으로 activation function을 거치는 과정에서 classification과 유사(거의 똑같은) 역할을 합니다.
- Decision Trees
- Random Forest
- XGBoost
- CNN (Convolution Neural Network)
- RNN (Recurrent Neural Network)
등이 있습니다.
위에서 언급한 모델은 Classification만을 위한 모델이 아니니 혼동이 없길 바랍니다.
Metric은 아니지만 매우 중요한 Matrix를 먼저 소개합니다.
Confusion Matrix

단순히 Actual class, Predicted class로 구분하여 만든 n*n metrix입니다.
이해가 직관적이어서 쉽다는 장점이 있지만 수치로 평가를 내리기에는 부적절하기 때문에 Metric으로 구분되지 않습니다.
Classification Accuracy
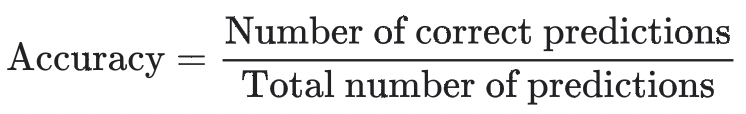
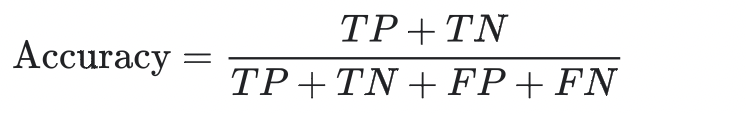
T : True / F : False / P : Positive / N : Negative
식을 쉽게 해석하자면 정말 단순히... prediction class와 actual class 가 같은 비율을 정의한 식입니다.
해당 metric을 classification category에서는 가장 폭넓게 자주 사용되는 모습을 보입니다.
하지만 해당 metric이 부적절한 indicator가 되는 경우를 보이기도 합니다.
예를 들어 위의 confusion matrix에서의 data의 accuracy를 측정한다고 가정해봅시다.
총 1100개의 데이터에서 non-catdmf predict한 결과는
1000 / 1100 = 0.909
입니다
해당 data는 imbalanced하기 떄문에 높은 Accuray를 얻을 수 있지만 상대적으로 적은 양의 data에 대해선 많은 것을 학습할 수 없기 때문에 accuracy는 높을 지언정 마냥 정확도가 높은 모델이라고 볼 수는 없습니다. (적은 validation data를 구분할 수 없기 때문에)
따라서 performance에 대한 metric도 함꼐 고려해볼 필요가 있습니다.
이 때 등장하는 metric이 3-Precision 입니다.
Precision

해당 관계식을 직관적인 식으로 변형하면 다음과 같습니다.
Precision = TP / (TP + FP)위에서 언급한 cat / non-cat 의 예시를 precision에 대입해보면
기존의 accuracy가 0.909가 나온데 비해
precision_cat = 90/(90+60) = 0.60
precision_non_cat = 940(950) = 98.9%
와 같이 나옵니다.
그렇다면 이 모델이 예측한 값은 reliable할 수 있는지에 대한 의문이 생기게 되고 해당 metric이 필요한 이유를 설명합니다.
Recall

위와 마찬가지로 해당 관계식을 간단한 식으로 정리해보면 다음과 같습니다.
Recall = TP / (TP + FN)따라서,
Recall_cat = 90/100 = 0.90
Recall_non_cat = 940/1000 = 0.94
F1-Score
F1-score는 간단히 말해 precision과 recall을 합친 개념입니다.

F-score의 대표격으로 쓰이는 F1-score는 다음과 같이 위에서의 예시를 계산할 수 있습니다.
F1_cat = 2 * 0.6 * 0.9 / (0.6 + 0.9) = 0.72
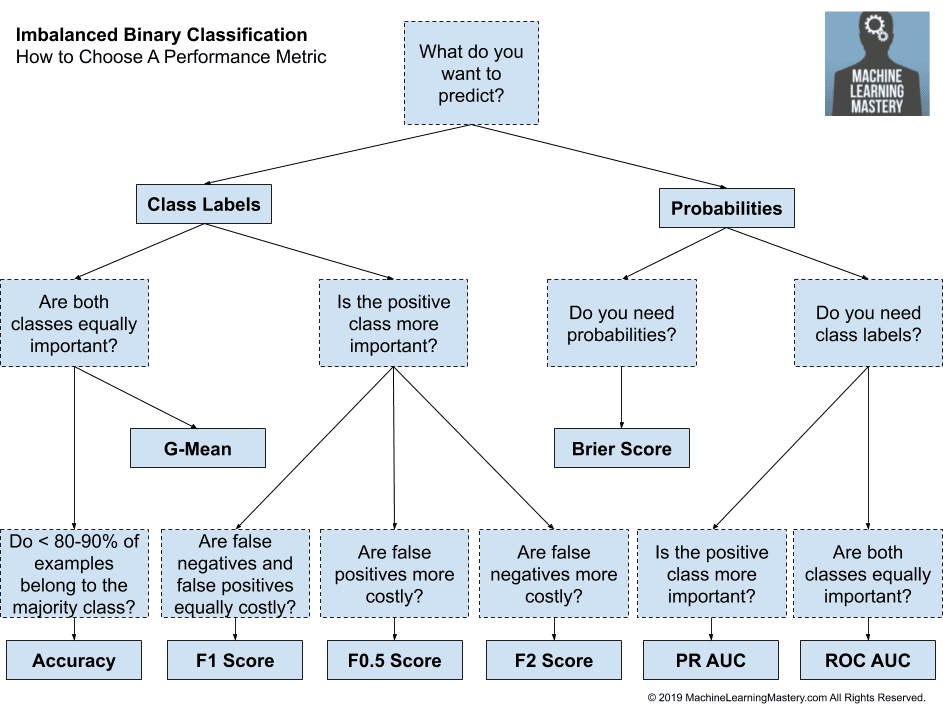
Regression
위의 classification에서도 언급한 바와 같이 ML의 대표적인 Category중 하나로 수많은 model들이 해당 task를 지원합니다.
target value가 continuous하다는 특징이 있어서 metric이 꽤나 중요하다는 특징을 가집니다.
하지만 정확하게 따지면 regression에 대해 accuracy를 구할 수는 없습니다.
그래서 error를 정의하고자 하는 식들이 존재합니다.
MSE (Mean Squared Error)
Regression문제에서 가장 많이 쓰이는 metric중 하나입니다.
해당 metric은 말 그대로 prection value와 actual value 사이의 "평균 제곱 오차"를 계산합니다.
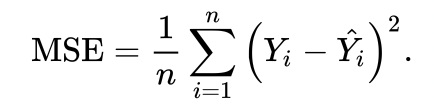
y : actual value
y-hat : predicted value
종종 MSE에 루트를 씌워 RMSE로 바꿔 사용하는 사람들도 있습니다. (평균 분포를 위해..!)
MAE (Mean Absolute Error)
MSE와 매우 유사한 특징을 가지는 MAE는 MAD(Mean Absolute Deviation)라고도 불립니다.
다만 outlier에 대해 매우 robust한 특징을 가집니다.
-> 제곱은 regression에 떨어진 outlier까지의 거리에 대해 더 멀리 보내버리는 특징을 가지기 때문

부정확한 내용이 있다면 댓글 및 메일 부탁드립니다.
Reference : https://en.wikipedia.org/wiki/, https://machinelearningmastery.com/, https://towardsdatascience.com/20-popular-machine-learning-metrics-part-1-classification-regression-evaluation-metrics-1ca3e282a2ce
'MACHINE LEARNING > Artificial Neural Network' 카테고리의 다른 글
| Few-Shot Learning? 관련 논문을 중심으로 이해해보자! (0) | 2022.12.27 |
|---|---|
| BART 논문 리뷰 / BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (0) | 2022.11.28 |
| NLP / BERT vs GPT 모델 비교 (0) | 2022.08.10 |
| BIDAF / Bidirectional Attention Flow for Machine Comprehension 논문 요약 (0) | 2022.08.07 |
| Gradient Descent / Stochastic Gradient Descent 개념적 비교 (0) | 2022.08.04 |