BART 논문 리뷰
paper source : https://arxiv.org/abs/1910.13461
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based
arxiv.org
본 논문을 이해하기 위해 다음 논문을 선행하시는 걸 추천드립니다🫡
0. Attention is all you need
paper source:https://arxiv.org/abs/1706.03762
1. BERT: Pre-trainig of Deep Bidirectional Transformers for Language Understanding
paper source:https://arxiv.org/abs/1810.04805
2. GPT : Generative Pre-Training (GPT)
Abstract
pretraining sequence-to-sequence model을 위한 denoising autoencoder -> BART
BART는 다음 두 가지 방법을 이용해 학습됩니다.
1. corrupting text with an arbitrary noising function / 임의 노이즈 제거 함수로 텍스트 손상
2. learning a model to reconstruct the original text / 원본 텍스트를 재구성하기 위한 모델 학습
뒤의 두 가지 방법은 BERT로, GPT 등으로 알려진 Transformer-based neural machine tranlation architecture를 사용합니다.
본 논문에서는 원본 문장의 순서와 한 개의 mask token이 대체된 텍스트를 randomly shuffle 하여 사용하는데, 특히 Fine-tuning 됐을 때 text generation task에 대해 좋은 성능을 보이며, comprehenstion task 또한 준수한 성능을 보입니다.
논문이 나왔을 당시 RoBERTa와 유사한 학습 환경에서 abstractive dialogue, QA, summarization에서 state-of-the-art를 기록했습니다.
Introduction
위의 Abstract에서 간략히 언급한 바와 같이 BART는 BERT의 특징과 GPT의 특징을 모두 학습 시 사용합니다.
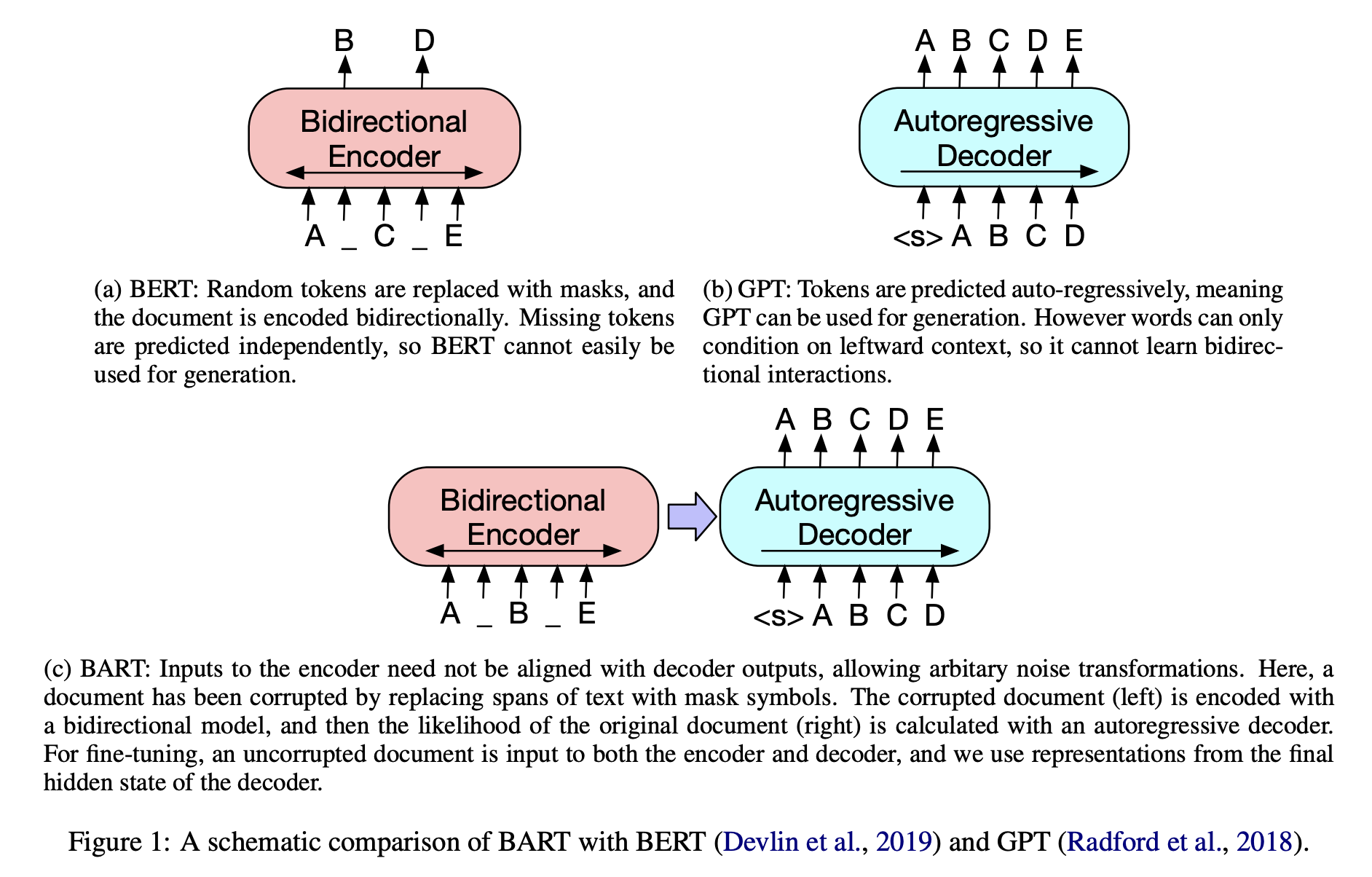
해당 Figure를 통해 알 수 있는 것은
* BERT의 경우 Bidirectional Encoder를 사용 -> generation에서 사용이 어려운 단점
* GPT의 경우 Autoregressive Decoder를 사용 -> bidirectional 정보를 얻을 수 없다는 단점
한다는 점입니다.
BART architecture에서는
1. corrupting text with an arbitrary noising function / 임의 노이즈 제거 함수로 텍스트 손상
2. learning a model to reconstruct the original text / 원본 텍스트를 재구성하기 위한 모델 학습
즉, BERT의 구조와 유사하게 손상된 text를 입력받아 bidirectional model로 encoding하여 정답 text에 대한 likehood를 autoregressive decoder로 계산합니다.
이런 설정은 noising이 자유롭다는 장점을 가지고, 해당 논문에선 문장 순서를 바꾸거나 임의 길이의 토큰을 하나의 mask로 바꾸는 등 여러 noising 기법을 evaluation합니다.
MODEL
- Sequence-to-Sequence transformer model
- ReLU activation function -> GeLUs
- base model : 6 layers
- large model : 12 layers
- decoder의 각 layer에서는 encoder의 마지막 hidden layer와 cross-attention - 기존의 transformer decoder와 유사
- BERT에서 사용한 additional feed-forward network 사용 X
최종적으로, BERT의 약 10%정도 더 parameters를 사용
BART는 corrupting documents를 통해 학습하고 reconstruction loss 를 optimizing합니다.
어떤 종류의 noise든 적용할 수 있다는 특징이 다른 auto-encoder model과의 차이입니다.

Figure 2에서 의미하는 바는 다음과 같습니다.
- Token Masking
- BERT와 유사, Random하게 [MASK] token을 채웁니다
- Token Deletion
- input에서 랜덤한 token들을 삭제합니다. model은 삭제된 token의 위치가 어디인지 알아내야합니다.
- Sentence Permutation
- document를 sentence로 나누고, random하게 순서를 shuffle합니다
- Document Rotation
- random하게 token을 하나 정해, 문서가 해당 token에서 시작하도록 회전합니다.
- model은 시작점을 예측합니다.
- Text Infilling
- 여러 개의 text span을 선택, 하나의 [MASK] 토큰으로 대체합니다. 이때 span의 길이는 Poisson distribution으로 정합니다.
- SpanBERT에서 착안한 점으로, 본 연구에서는 span의 길이를 model이 알지 못하는 상태입니다.
- 따라서 model은 document의 시작점을 예측해야합니다.
BART의 fine tuning은 downstream application에 대해 다음과 같이 제안합니다.

- Sequence Classification Tasks
- decoder에서 attention을 계산할 수 있도록 합니다.
- 즉, final decoder token의 final hidden state은 multi-class linear classifier에 전달됩니다.
- BERT의 CLS token과 유사하게, final token의 representation까지 추가합니다.
- Token Classification Tasks
- complete document를 encoder, decoder에 각각 전달합니다.
- 각 top hidden state를 사용하여 classification을 수행합니다.
- Sequence Generation Tasks
- autoregressive decoder를 포함하는 model이기에 QA나 summarization을 바로 finetuning할 수 있습니다.
- encoder의 input은 input sequence
- decoder의 output은 autoregressive
- Machine Translation
- BART 모델 전체를 machine translation decoder로 사용, bitext로 학습된 새로운 encoder parameter를 추가하여 진행
- BART encoder의 embedding layer를 새로운 randomly initialized encoder로 교체
- end-to-end 학습
- 새로운 encoder는 foreign words를 mapping하도록 학습, BART가 이를 영어로 denoise
- 이때 encoder는 기존의 BART와 다른 vocabulary를 사용해도 무관
- source encodere를 두 단계로 학습
- BART의 output으로부터 cross-entropy loss를 backpropagating (두 단계 모두 해당)
- 1. freeze most parameters / update the randomly initialized source encoder / BART positional embedding / self attention input projection matrix of BART's encoder first layer
- 2. 적은 수의 iterations로 model parameters 학습
기존의 연구에 비해 더 많은 nosing scheme 지원
- Comparison Objectives
- Language Model
- Permuted Language Model
- Multitask Masked Language Model
- Masked Seq-to-Seq
* model의 성능 비교 부분이므로 자세한 내용은 원문을 참고해주세요
Result

- 결론 및 모델 자랑부분..
- Performance of pre-training methods varies significantly across tasks
- Token masking is crucial
- Left-to-right pre-training improves generation
- Bidirectional encoders are crucial for SQuAD
- The pre-training objective is not the only important factor
- Pure language models perform best on ELI5
- BART achieves the most consistently strong performance.
이후는 large model의 성능 평가가 이어집니다.





Conclusions
- corrupted documents를 original으로 reconstruct하도록 학습하는 BART 모델을 제안
- BART는 discriminative task에서 RoBERTa와 비슷한 성능을 달성.
- Generation Task에서는 SOTA 성능을 달성
- 추가 연구로 pre-training을 위해 corrupting documents에 대한 새로운 방법을 제안
'MACHINE LEARNING > Artificial Neural Network' 카테고리의 다른 글
| Attention / 어텐션이란 무엇인가? (분량 주의) (0) | 2023.01.09 |
|---|---|
| Few-Shot Learning? 관련 논문을 중심으로 이해해보자! (0) | 2022.12.27 |
| ML / Metric 종류 및 특징 정리 (0) | 2022.09.09 |
| NLP / BERT vs GPT 모델 비교 (0) | 2022.08.10 |
| BIDAF / Bidirectional Attention Flow for Machine Comprehension 논문 요약 (0) | 2022.08.07 |