유용한 AI SaaS Application을 구축하려면 모델이 사용자의 외부 데이터에 액세스할 수 있어야 합니다.
그렇다면, RAG(Retreival Augemented Generation) vs. Fine-Tuning 중 어느것을 사용해야 할까요?
이번 글에서는 SaaS Application 관점에서 두 가지 접근 방식을 비교하고자 합니다.
🤣단순 비교만 원하시는 분은 마지막 Conclusion의 표를 확인하시면 됩니다🤣
Introduction
Multi-Tenant (클라우드의 하나의 자원을 쪼개서 서비스 사용자에게 제공; 마치 하나의 집을 쪼개서 빌려주는 개념) AI SaaS Application을 구축하려는 경우, Prompt Engineering(프롬프트 엔지니어링)에만 의존하는 한계를 경험했을 것입니다.
기본적인 프롬프트를 완벽하게 작성하더라도, GPT-4, Llama-3 같은 범용 모델은 사용자 고유의 데이터를 포함하지 않기 때문에 context가 부족하여 제한적입니다.
예를 들어, AI 고객 서비스 챗봇을 판매한다고 가정해봅시다. 고객의 데이터(과거 대화, 제품 정보 등)에 접근할 수 없다면 챗봇은 쓸모가 없게 됩니다.
보통의 경우, 이러한 데이터는 고객의 CRM, 문서, 티켓 시스템 등 다른 애플리케이션에 저장되어 있죠.
그렇다면 이러한 Context Data를 LLM에 어떻게 활용할 수 있을까요?
제 3자 소스로부터의 데이터를 LLM과 함께 사용하는 주요 접근법은 RAG와 Fine-Tuning입니다.
RAG vs. Fine-Tuning
Retrieval Augmented Generation (RAG)
RAG는 외부 데이터를 실시간으로 검색하여 프롬프트에 Context를 주입함으로써 대형 언어 모델의 정확성을 높이는 과정입니다.
이 데이터는 고객의 문서, 웹 페이지 등 다양한 소스에서 가져올 수 있습니다.

데이터 수집/저장
- 초기 수집 작업: 고객이 제공한 모든 관련 데이터를 초기 수집합니다.
- 백그라운드 작업: 새로운 정보가 생길 때마다 실시간으로 데이터를 업데이트합니다.
- 임베딩 및 저장: 수집한 데이터를 벡터 데이터베이스에 저장하여 검색할 수 있도록 임베딩을 생성합니다.
프롬프트 주입
- 실시간 검색 및 주입: 벡터 데이터베이스에서 가장 관련성 높은 텍스트를 검색하여 초기 프롬프트에 주입합니다.
Fine-Tuning
Fine-Tuning은 사전 훈련된 LLM을 특정 도메인 데이터셋으로 추가 학습시켜 특정 작업에서 성능을 높이는 과정입니다.
주요 차이점
Fine-Tuning은 LLM의 파라미터를 수정하며, 배포 전에 수행됩니다.
Clean한 훈련 데이터셋을 얻는 것이 어렵고 시간이 많이 걸리지만, 예측 가능한 결과를 제공합니다.
RAG
도메인 특정 데이터셋을 바로 사용할 수 없다면, Fine-Tuning보다는 RAG를 우선시하는 것이 좋습니다.
다음과 같은 이유 때문입니다:
- RAG는 실시간 또는 거의 실시간의 Context를 프롬프트에 주입할 수 있습니다.
- RAG는 Clean하고 Structured 훈련 데이터셋이 필요하지 않습니다.
- RAG는 여러 데이터 소스에서 관련 Context를 검색할 수 있습니다.
그럼, 이제 RAG와 구현 방법을 조금 더 깊이 파헤쳐보겠습니다.
RAG with Third-Party Data
1. Data Ingestion
첫 번째 단계는 유저의 external contextual data가 어디에 있는지 파악하는 것입니다.
(즉 내가 원하는 데이터는 어디있고, 그 중 어떤걸 사용할 것인지에 대한 명확한 정의가 필요합니다.)
예를 들어, product knowledge가 Notion 워크스페이스나 Google Drive의 온보딩 문서에 저장되어 있을 수도 있고,
공통 Q&A는 Slack 스레드에, 판매 이메일은 Salesforce/Salesloft에, 통화 기록은 Gong이나 Zoom 등에 저장될 수 있습니다.
어디에서 데이터를 가져올지 파악한 후에는 기존 데이터를 모두 수집하고, 해당 데이터 소스의 업데이트를 반영하는 메커니즘을 구축해야 합니다.
데이터 수집 엔진을 구축 시 고려사항:
- Authentication: 각 3자 API마다 OAuth 정책이 다르므로 항상 토큰을 갱신하여 연결 상태를 유지해야 합니다.
- Webhooks/CRON jobs: 각 앱의 각 객체 유형에 대해 webhook listener나 CRON 작업을 설정하고, Activate 상태를 확인하는 모니터링 메커니즘을 구축해야 합니다.
- Horizontal Scaling: 초기 수집 작업에서 모든 고객의 기존 데이터를 수집하면 수백만, 수십억 개의 요청이 한꺼번에 발생할 수 있습니다. 이러한 데이터를 처리할 수 있도록 인프라가 자동으로 확장되어 서버가 죽지 않도록 해야 합니다.
- Rate Limits: 통합해야 하는 각 서드파티 API에는 속도 제한이 있을 수 있습니다. 만약 속도 제한에 걸릴 경우, 작업 실패를 방지하기 위해 auto-retry 및 Queuing 메커니즘을 갖추어야 합니다.
- Security: 수집한 데이터는 안전하게 저장되고 SaaS application의 multi-tenant 특성상 고객의 인스턴스 간에 격리되어야 합니다.
- Breaking Changes: 3자 API는 종종 변경 사항을 발표하므로 팀이 이를 신속하게 대응해야 합니다.
2. Chunking (Tokenization)
대부분의 Contextual Data는 Unstructured Data이므로 대량의 문자열을 처리하게 됩니다.
LLM의 짧은 Context Window 때문에 고객의 모든 데이터를 각 프롬프트에 주입할 수 없습니다(비효율적이기도 합니다).
3. Generate Embedding
RAG 프로세스가 실행 시 가장 관련성 높은 데이터를 검색할 수 있도록 청크를 벡터화하여 숫자 표현으로 변환해야 합니다.
이를 위해 사용할 수 있는 Embedding 모델은 많으며, Huggingface의 리더보드에서 최신 벤치마크 기반 상위 모델을 확인할 수 있습니다.
https://huggingface.co/models?language=ko
Models - Hugging Face
huggingface.co
4. Storing in a Vector Database
수집한 데이터에서 Embedding을 생성한 후 이를 Vector Database에 저장해야 합니다.
데이터를 벡터로 저장하면 대량의 데이터를 신속하게 유사성 검색할 수 있으며, 이는 방대한 지식 기반을 가진 RAG에 필수적입니다.
The vector database to build knowledgeable AI | Pinecone
Search through billions of items for similar matches to any object, in milliseconds. It’s the next generation of search, an API call away.
www.pinecone.io
5. Runtime Retrieval
실행 시, 사용자가 쿼리를 보내면 해당 쿼리를 벡터화하여 벡터 데이터베이스에서 유사성 검색을 수행해야 합니다.
이를 통해 가장 관련성 높은 Context Chunk를 검색하고, 이를 선택한 LLM(e.g. GPT, Llama 등)의 프롬프트에 포함시킵니다.
이렇게 하면 LLM이 검색된 정보를 활용하여 사용자 쿼리에 대해 더 개인화되고 관련성 높은 포괄적인 응답을 생성할 수 있습니다.
Fine-Tuning
이제 multi-tanent SaaS 에서 Fine-Tuning이 어떻게 작동하는지 살펴보겠습니다.
다음은 Pre-trained model 을 Fine-Tuning하는 과정의 세부 사항입니다.
1. Data Ingestion
RAG와 마찬가지로, 사용자의 외부 애플리케이션에서 데이터를 수집하여 훈련 데이터셋을 구축해야 합니다.
여기에는 판매 참여 플랫폼의 판매 이메일, Intercom의 대화 기록, CRM의 판매 성과 데이터 등이 포함될 수 있습니다.
2. Preparation
RAG와 달리, 이 데이터는 Fine-Tuning에 사용될 수 있도록 준비되고 정리되어야 합니다.
기본적으로, 모델을 Fine-Tuning하기 위해 훈련, 검증, 테스트 데이터셋이 필요합니다. 다음은 훈련 데이터셋의 예시입니다:
- AI 지원 챗봇을 위한 훈련 데이터셋:
- Input: 고객에 대한 모든 접근 가능한 데이터와 제출한 티켓
- Output: 지원 담당자가 제공한 응답
- AI 콘텐츠 작성자를 위한 훈련 데이터셋:
- Input: 고객의 블로그 개요
- Output: 해당 개요로 작성된 블로그 게시물
이 과정에서 가장 까다로운 점은 테스트 데이터셋이 깨끗하고 최적의 입력만을 포함하도록 하는 것입니다.
이 때문에 일부 AI SaaS 회사는 고객과 함께 훈련 데이터셋을 검증하는 On-Boarding을 요구하기도 합니다.
3. Fine-Tune and Validate
대부분의 회사에서는 기본 모델의 실제 파라미터를 수동으로 설정하는 것이 계산적으로 의미가 없습니다. 대신, Fine-Tuning(위에서 언급한 예시)을 통해 제한된 데이터셋으로도 기본 LLM을 훈련시킬 수 있습니다.
모델을 Fine-Tuning한 후에는 검증 세트를 사용하여 원하는 응답이 나오는지 테스트하고 검증해야 합니다. 결과가 만족스럽지 않으면 추가 데이터를 사용하여 모델을 계속 Fine-Tuning해야 하며, 제품 준비가 완료되면 Fine-Tuning된 모델을 배포합니다.
4. Reinforcement Learning
운영 중에는 사용자 피드백을 통한 강화 학습(RLHF) 루프를 도입할 수 있습니다.
기본적인 형태로, 사용자가 받은 응답을 평가할 수 있는 기능을 제공하고, 그 평가를 모델의 성능을 높이는데 활용할 수 있습니다.
그러나 이는 사용자의 행동, 예를 들어 사용자가 명확한 질문을 했는지, 사용자 감정, 또는 생성된 출력을 그대로 사용했는지 여부(특히 AI 콘텐츠 생성 맥락 내에서) 등에 기반하여 상당히 정교해질 수 있습니다.
※ 아래 링크를 따라 Fine-Tuning 을 위한 파이프라인을 코드와 함께 확인해보세요.
https://huggingface.co/learn/cookbook/fine_tuning_code_llm_on_single_gpu
Fine-tuning a Code LLM on Custom Code on a single GPU - Hugging Face Open-Source AI Cookbook
LLM and RAG recipes with other Libraries
huggingface.co
Conclusion
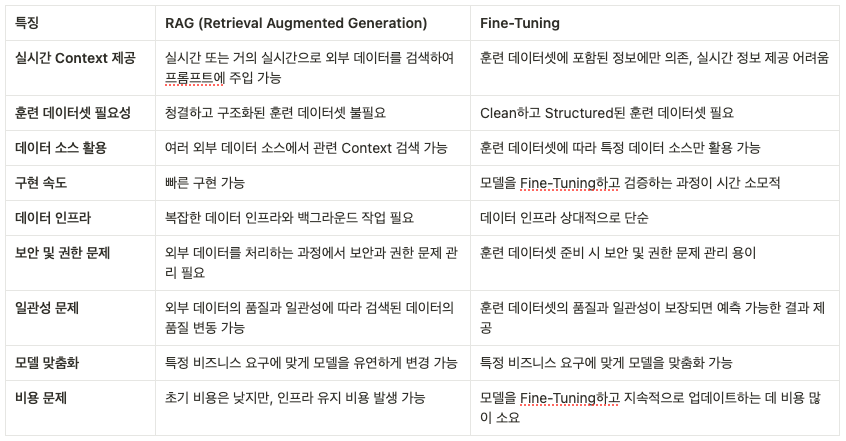
말이 길었지만, 결국 간단하게 정리하면 다음과 같습니다.
RAG는 빠르게 구현할 수 있고 실시간 정보를 제공할 수 있어 유연한 장점이 있지만, 복잡한 인프라와 보안 문제를 해결해야 합니다.
반면, Fine-Tuning은 특정 도메인에 최적화된 성능을 제공하지만, 훈련 데이터셋 준비와 모델 업데이트에 많은 시간과 비용이 소요됩니다.
대부분의 경우, 초기에는 RAG를 우선시하고, 필요에 따라 Fine-Tuning을 고려하는 것이 효율적일 수 있습니다.
Reference
https://www.useparagon.com/blog/rag-vs-finetuning-saas
https://pvml.com/glossary/retrieval-augmented-generation-rag/
https://neo4j.com/developer-blog/fine-tuning-retrieval-augmented-generation/
'MACHINE LEARNING' 카테고리의 다른 글
| Time series classification 데이터 전처리 (0) | 2024.09.01 |
|---|---|
| 완전한 오픈소스와 언어모델 / OLMo: Open Language Model (0) | 2024.02.11 |
| 논문 리뷰 / RAG VS FINE-TUNING: PIPELINES, TRADEOFFS, AND A CASESTUDY ON AGRICULTURE (0) | 2024.01.28 |
| OpenAI Assistant API 활용 예제 (Python Code) / ChatGPT (0) | 2023.11.12 |
| 중심극한정리 / Central Limit Theorem 에 대해 알아보자 (0) | 2023.04.22 |