Matching the Blanks: Distributional Similarity for Relation Learning
논문 원문 : https://arxiv.org/pdf/1906.03158.pdf
prerequirement
transformer neural network architecture에 대한 기본 지식이 있어야합니다!
- entity pair의 관계를 encoding하는 부분..!

Abstract
기존의 일반적인 General purpose relation extractors 는 Information extraction(이하 IE)의 주요한 목표였습니다.
다만 generalize 능력의 한계가 있어왔습니다.
해당 논문에서는 관계에 대한 extensions of Harris’ distributional hypothesis를 build합니다.
또한 task에 구애받지 않는 관계를 구축하기 위해 text-representation(특히 BERT)를 포함합니다.
Introduction
entity간의 관계를 파악하거나 추출하는 것은 NLP의 오래된 목표 중 하나입니다.
일반적으로 해당 목표를 이루기 위해 다음과 같은 노력들이 있었습니다.
- supervised 혹은 distantly supervised relation extractors
- (제한된 스키마에서 텍스트로부터 관계를 매핑하는 것..)
- open information extraction removes the limitations of a predefined schema
- 스코프를 늘리긴 하지만 an associated lack of generality를 유발.
- the universal schema
- joint-representation을 구축하기 위해 텍스트의 다양성과 개략적인 관계의 간결한 본질을 모두 수용
Architectures for Relation Learning
- 주요 목적 : 텍스트로부터 관계를 추출하는 모델 개발
- BERT를 basis로 설정합니다.
Relation Classification and Extraction
Fully supervised relation extration / few-shot relation matching
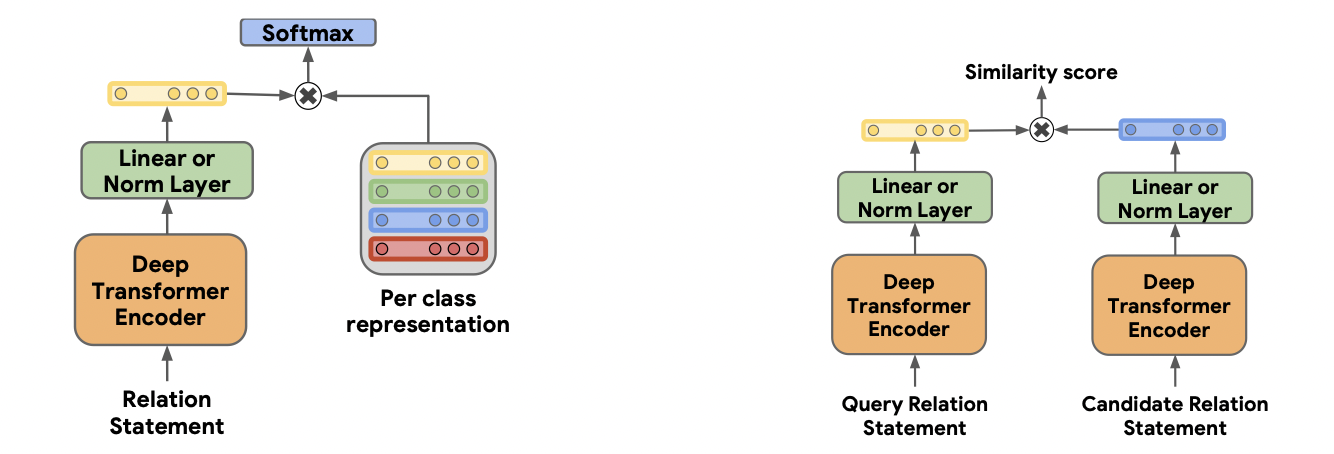

Relation Representations from Deep Transformers Model
BERT 모델에 input을 넣기 위해 ENTITY MARKERS라고 부를 start/end 마커를 각 엔티티에 지정합니다.
해당 인코더로부터 fixed length relation representation을 추출, [CLS] 토큰, 엔티티 멘션 풀링, 엔티티 스타트 상태를 포함합니다.
하이퍼-파라미터는 다음과 같습니다.

위와 같이 설계된 모델을 바탕으로 blanks matching traning을 수행합니다.
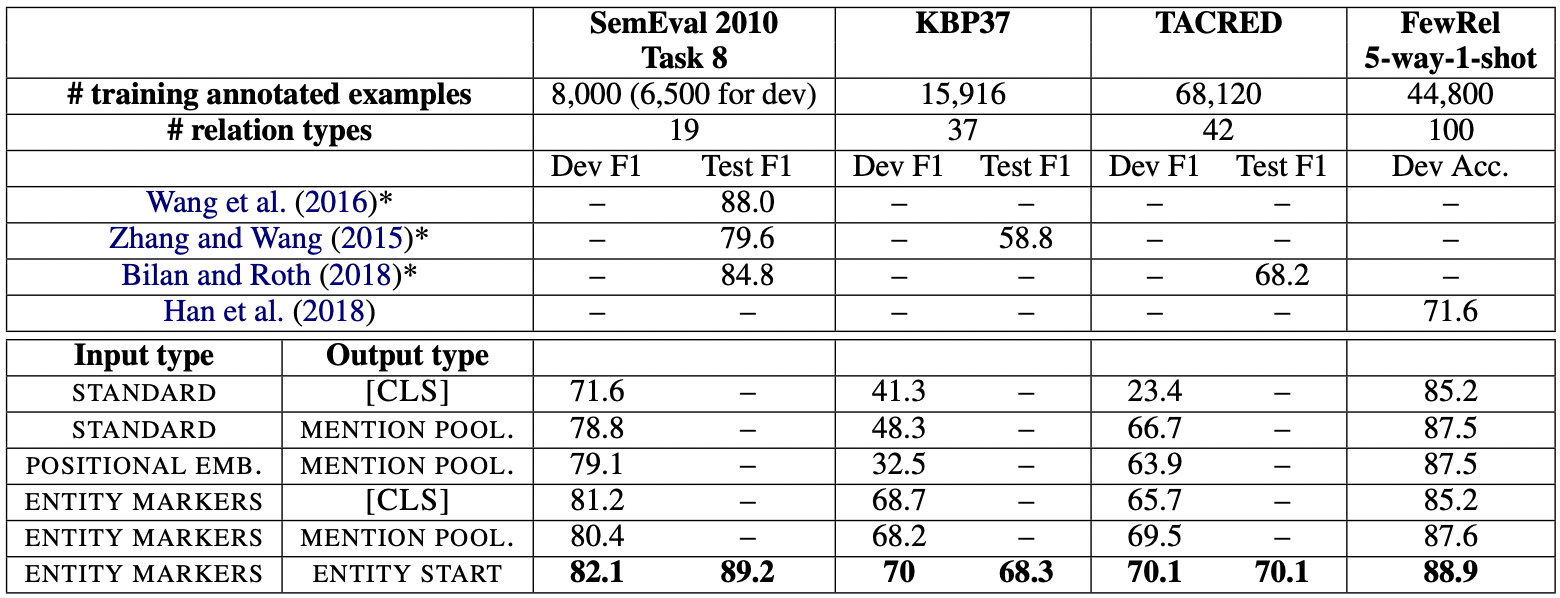
결과는 다음과 같습니다.
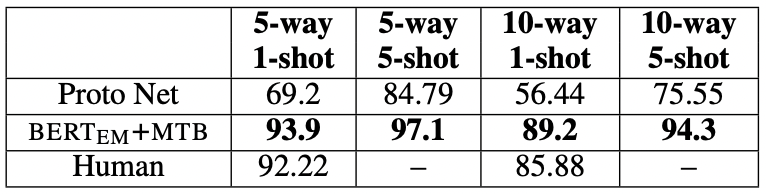
다음과 같은 파라미터로 evaluation을 수행합니다.


Supervised Relation Extraction / Result

Conclusion
해당 논문에서는 BERT 모델을 기반으로 relation extraction을 수행할 때 성능 향상을 위한 방법론 중 한가지를 제시합니다.
entity markers를 통해 관계 추출에 있어서 힌트를 제공함으로써 성능 향상에 기여합니다.
추가로 clustering을 해당 흐름에 더해 성능 향상을 기대할 수 있을 것입니다.
번역 오류 및 정리하는 과정에서 개념적 오류가 생길 수 있습니다. 수정 사항이 발견되면 댓글이나 메일 주세요
'MACHINE LEARNING' 카테고리의 다른 글
| Approximate inference 정리 (0) | 2023.02.21 |
|---|---|
| Bias-Variance tradeoff 관계 해석 (0) | 2023.02.19 |
| Word2Vec 개념 정리 (0) | 2022.12.30 |
| ML / 3가지 주요 원칙 (2) | 2022.09.16 |
| Wandb / Quick Start 흐름 (0) | 2022.08.06 |