Weights & Biases is the machine learning platform for developers to build better models faster
🔥 Simple Pytorch Neural Network

import random
# Launch 5 simulated experiments
total_runs = 5
for run in range(total_runs):
**# 🐝 1️⃣ Start a new run to track this script**
wandb.init(
# Set the project where this run will be logged
project="basic-intro",
# We pass a run name (otherwise it’ll be randomly assigned, like sunshine-lollypop-10)
name=f"experiment_{run}",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# This simple block simulates a training loop logging metrics
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 🐝 2️⃣ **Log metrics from your script to W&B**
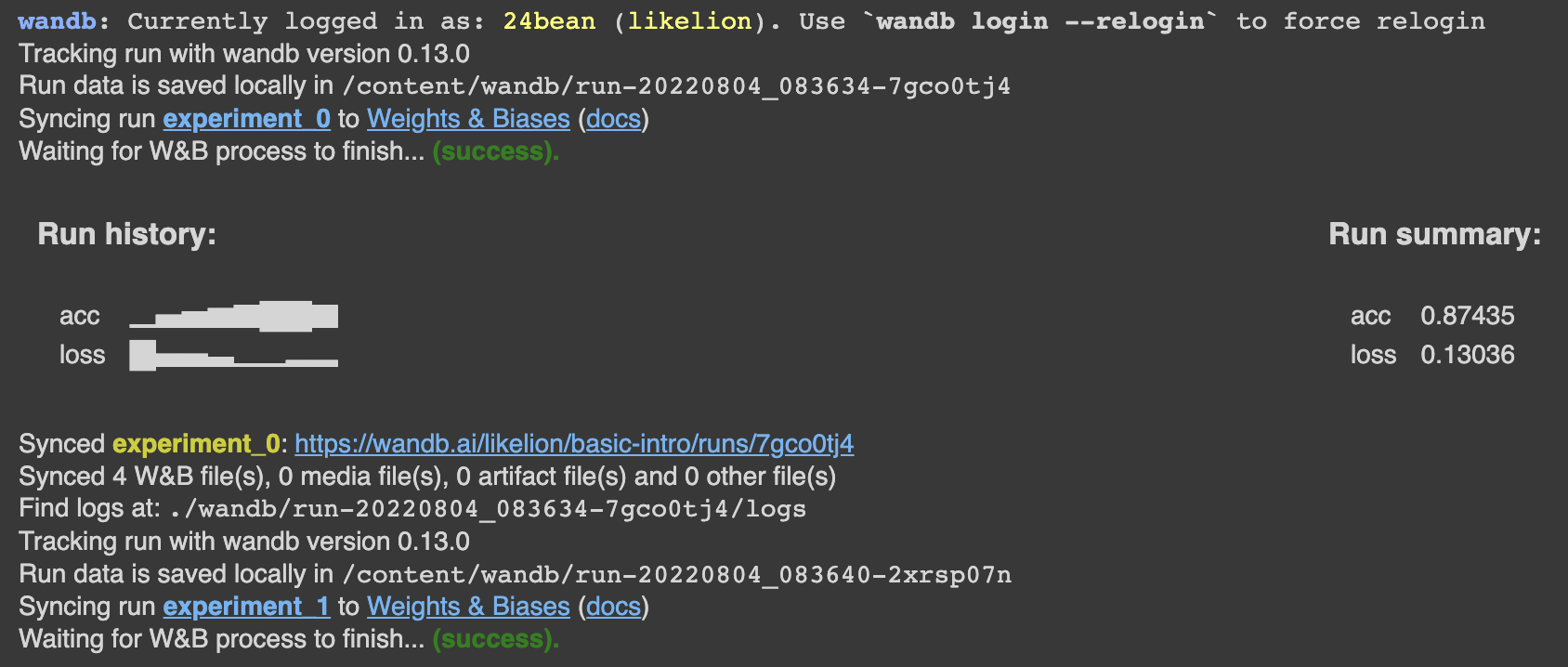
wandb.log({"acc": acc, "loss": loss})
# Mark the run as finished
wandb.finish()

Train Your Model
**# Launch 5 experiments, trying different dropout rates**
for _ in range(5):
# 🐝 initialise a wandb run
wandb.init(
project="pytorch-intro",
config={
"epochs": 10,
"batch_size": 128,
"lr": 1e-3,
"dropout": **random.uniform(0.01, 0.80),**
})
# Copy your config
config = wandb.config
# Get the data
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2*config.batch_size)
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
# A simple MLP model
model = get_model(config.dropout)
# Make the loss and optimizer
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
# Training
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {"train/train_loss": train_loss,
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch)) / n_steps_per_epoch,
"train/example_ct": example_ct}
if step + 1 < n_steps_per_epoch:
**# 🐝 Log train metrics to wandb**
wandb.log(metrics)
step_ct += 1
val_loss, accuracy = validate_model(model, valid_dl, loss_func, log_images=(epoch==(config.epochs-1)))
**# 🐝 Log train and validation metrics to wandb**
val_metrics = {"val/val_loss": val_loss,
"val/val_accuracy": accuracy}
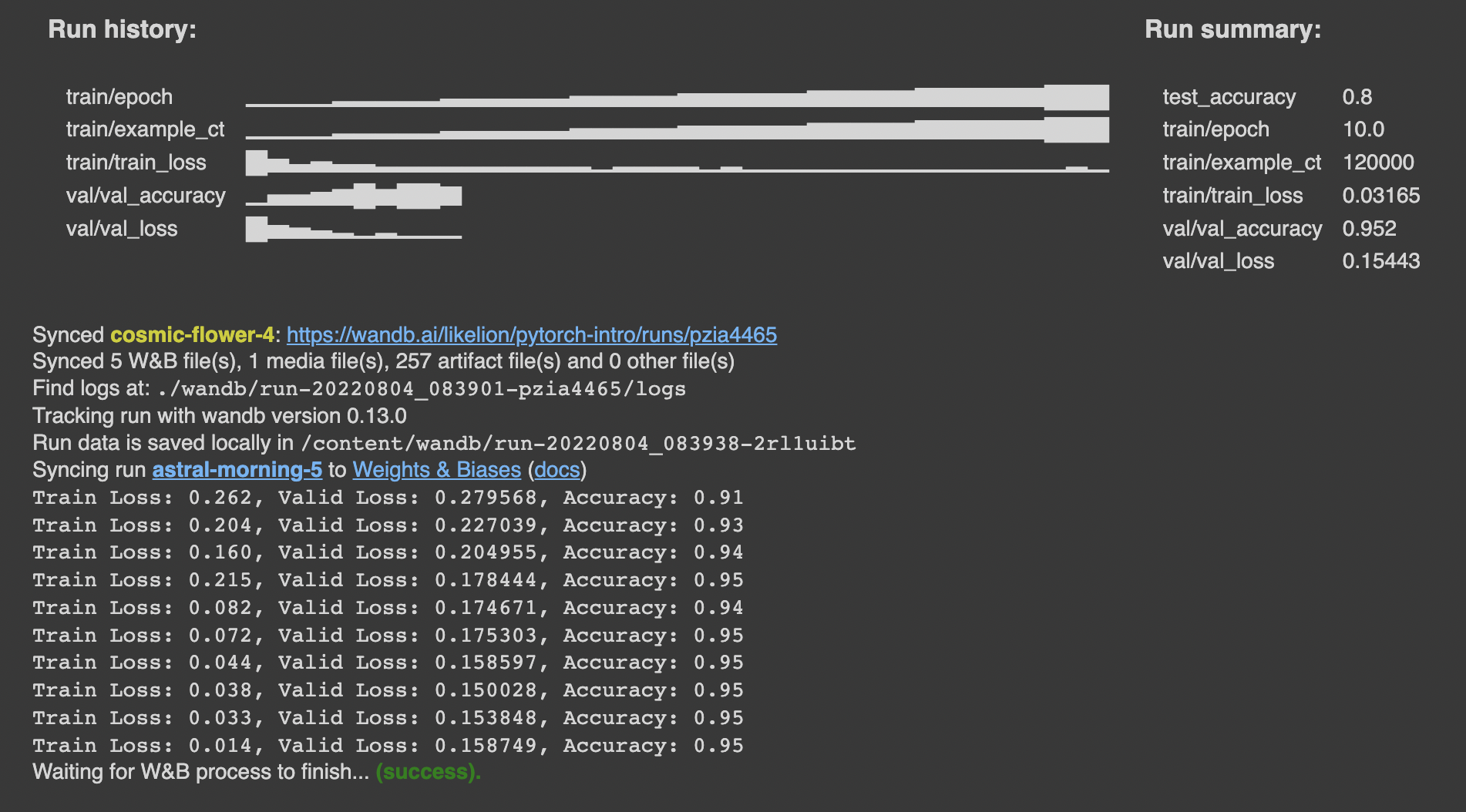
wandb.log({**metrics, **val_metrics})
print(f"Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}")
# If you had a test set, this is how you could log it as a Summary metric
wandb.summary['test_accuracy'] = 0.8
# 🐝 Close your wandb run
wandb.finish()

W&B Alerts
# Start a wandb run
wandb.init(project="pytorch-intro")
# Simulating a model training loop
acc_threshold = 0.3
for training_step in range(1000):
# Generate a random number for accuracy
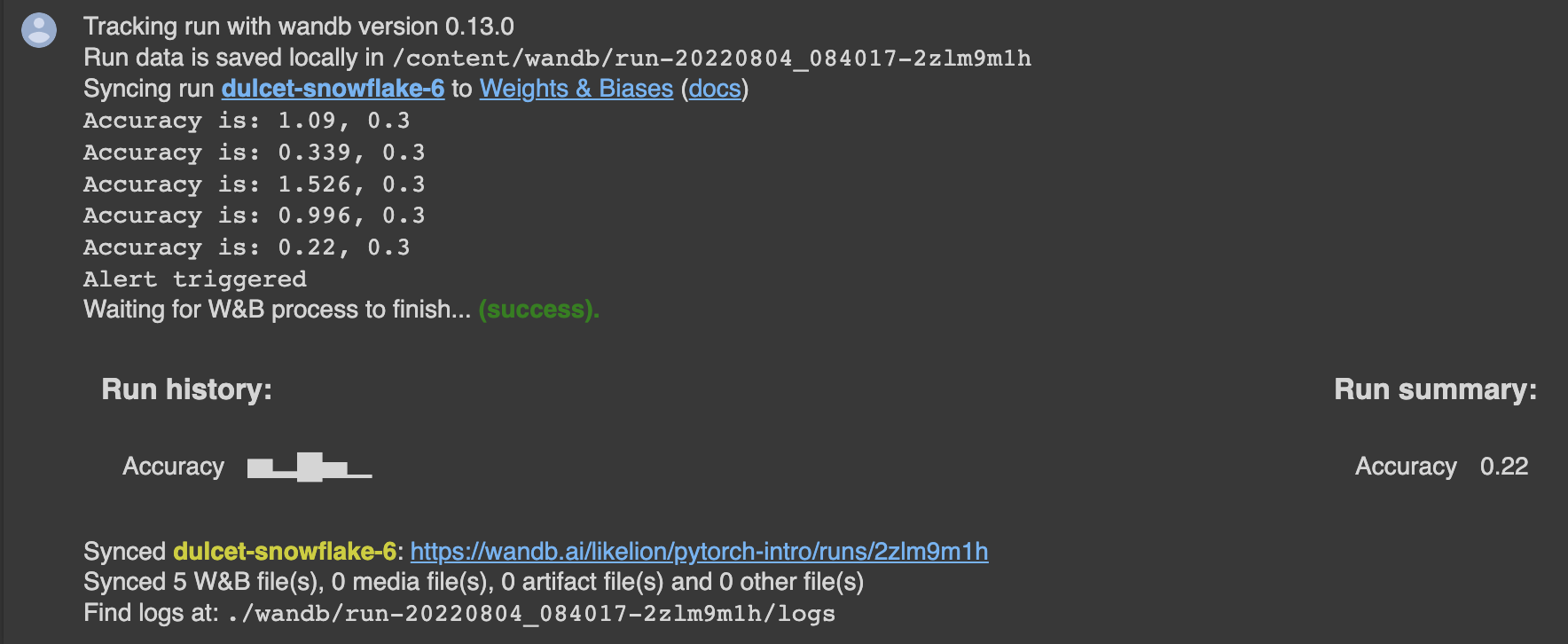
accuracy = round(random.random() + random.random(), 3)
print(f'Accuracy is: {accuracy}, {acc_threshold}')
# 🐝 Log accuracy to wandb
wandb.log({"Accuracy": accuracy})
# 🔔 If the accuracy is below **the threshold**, fire a W&B Alert and stop the run
if accuracy <= acc_threshold:
# 🐝 **Send the wandb Alert**
wandb.alert(
title='Low Accuracy',
text=f'Accuracy {accuracy} at step {training_step} is below the acceptable theshold, {acc_threshold}',
)
print('Alert triggered')
break
# Mark the run as finished (useful in Jupyter notebooks)
wandb.finish()

Hyperparameter Sweeps using W&B
# dictionary 형식으로 입력
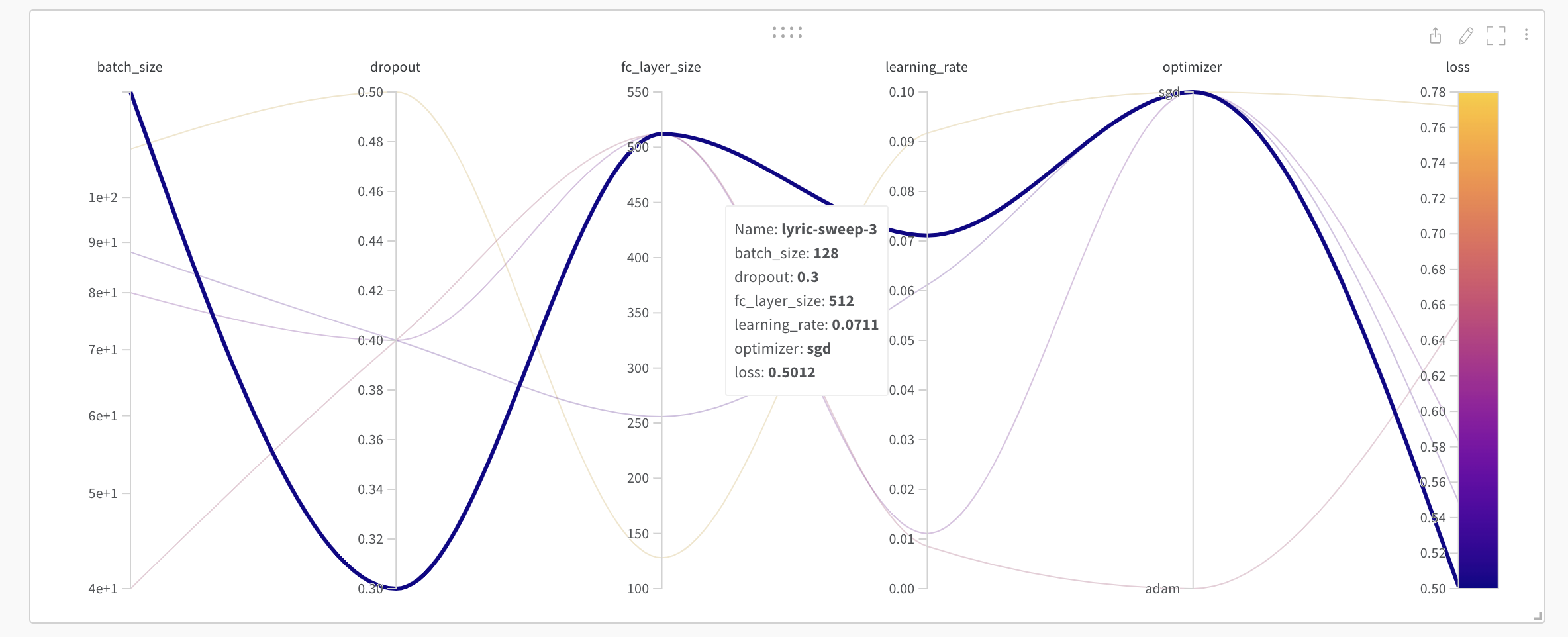
sweep_config = {
'method': 'random'
}
import pprint
pprint.pprint(sweep_config)
# output of sweep_config
{'method': 'random',
'metric': {'goal': 'minimize', 'name': 'loss'},
'parameters': {'batch_size': {'distribution': 'q_log_uniform_values',
'max': 256,
'min': 32,
'q': 8},
'dropout': {'values': [0.3, 0.4, 0.5]},
'epochs': {'value': 1},
'fc_layer_size': {'values': [128, 256, 512]},
'learning_rate': {'distribution': 'uniform',
'max': 0.1,
'min': 0},
'optimizer': {'values': ['adam', 'sgd']}}}
Initialize the Sweep
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")

Run the Sweep agent
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train(config=None):
# Initialize a new wandb run
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch})
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# download MNIST training dataset
dataset = datasets.MNIST(".", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # fully-connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
wandb.agent(sweep_id, train, count=5)

Reference : https://wandb.ai/site
반응형
'MACHINE LEARNING' 카테고리의 다른 글
| Approximate inference 정리 (0) | 2023.02.21 |
|---|---|
| Bias-Variance tradeoff 관계 해석 (0) | 2023.02.19 |
| Word2Vec 개념 정리 (0) | 2022.12.30 |
| ML / 3가지 주요 원칙 (2) | 2022.09.16 |
| NLP / Matching the Blanks: Distributional Similarity for Relation Learning 논문 요약 (0) | 2022.08.28 |